
In the era of digital transformation, both your customers and employees expect seamless and frictionless access to information and support. Search capabilities perfected by Google and Microsoft were the gold standard for knowledge retrieval but are insufficient in answering questions in a timely fashion. They can help find a specific needle in a proverbial data haystack but require you to know exactly what you are looking for and use specific or similar terms to retrieve that. Even if you craft the necessary keywords to retrieve the relevant document you still struggle with the problem of reading, comprehending and synthesizing that data to answer the question you initially came to answer. To identify the search functionality and examine the various articles available, extra clicks are required.
Chatbots and virtual assistants powered by Large Language Models (LLM) have emerged as valuable tools to meet this need by providing customer service and answering queries in a more natural form – conversationally via dialogue. With the advancements of Transformers and Attention we have, as a foundation, a general purpose chatbot able to converse in multiple languages on a plethora of topics.

Can you hire a chatbot to guide your sales team?
Today’s Generative AI’s (ChatGPT, Gemini, etc), advanced as they may be, are akin to hiring a digital Ken Jennings, the 74 win consecutive Jeopardy champion and now host. Ken is undoubtedly a master of trivia and conversational enough to be a host on TV but it turns out he knows little to nothing about your business itself. He may know a few things about the industry that he has read over time and can recall or may have heard of your company but he simply doesn’t know your sales playbook, your top product features or what is the turnaround time for lead handling on priority leads at your company.

He’s not Kenough
Ken may be the paragon of trivia but he needs to study your knowledge assets to be helpful. You could give him all of your company information and train him to enhance or fine-tune his cognition but that’s going to take a long time and be very costly. You’ll have to pay for him to spend time learning and every time you add or update knowledge assets you will need to retrain him at that high cost. Recency of that information will suffer in the meantime as you have to wait until Ken is retrained to answer correctly. A decision needs to be made on if you train him incrementally or start from base Ken and train him on everything you’ve accumulated all at once.
While he has great trivia retention when he started he is prone to forgetting, being biased by new things as he tries to put into context of things he knows and also extrapolating incorrectly too. You could also train him from scratch on a curated full corpus of knowledge and not the open internet but doing that requires 50-foot yacht money and years of compute hours.
On Jeopardy, Ken would make intelligent guesses for answers he didn’t truly know. They were quite plausible to be correct and often “pretty close” but ultimately some were wrong. He’d be convincing when he responded but anyone relying on that response would ultimately be wrong.
If you can’t trust his answers, you’d probably question where he’s getting his information. Ken, unfortunately like nearly all humans, can’t remember exactly when and where he read a fact that he was basing his answer on. Provenance of data and the full article it was obtained from would be helpful context for some people.
To summarize, digital Ken has the following problems that need to be addressed:
- Accuracy: You can’t trust that he will get the right information from all the trivia he has been trained on.
- Faithfulness: You can’t trust that he will hallucinate an answer and still answer confidently incorrect.
- Cost: Training an LLM from scratch is extremely costly and takes too long. Fine-tuning an LLM on private data is also cost prohibitive for most businesses and still takes a long time.
- Recency: You can’t trust that he has more recent information until he can be retrained on it.
- Provenance: You can’t verify the source he got that information from because he can’t tell you where he remembered it from.
RAG Time
So how can we build a chatbot that gets relevant data, synthesize it and speak to it authoritatively? Implementing Retrieval Augmented Generation (RAG) as a strategy gives us that capability by marrying the groundbreaking chatbot capabilities, and specifically the Question and Answer emergent behavior of a LLM, with the information we retrieve.
We can find relevant information for a given question by:
- Keyword Search: Here we can rely on the tried and true ‘lexical’ search capabilities offered by ElasticSearch or Solr to retrieve the top few articles in a knowledge base. That can be scored by both relevancy and recency.
- Semantic Search: We can also query for items that are semantically similar to the question. We can do this by storing our articles in a vector database and then querying with the question for items that are nearby in the embedding space.
- Structured query: If our dataset is columnar or having a structured layout we can leverage that information to query specifics about the data and retrieve the most relevant data from that query.
As an optimization, we can pick a hybrid approach whereby we execute 2 or more of the above options and aggregate the results to find more relevant data to use to answer a question. In this way, Ken can find the relevant information needed to answer a question using keywords but also through sentences that are semantically similar to the words in the question.
Arguing Semantics
So how do we find things that are semantically similar? The latent space, also known as latent feature space or embedding space, is a high dimensionality mathematical construct, well beyond 3D, where similar items will be closer to each other. An embedding is often represented as a multidimensional set of coordinates, say 768 dimensions, such that words that are similar in meaning will have numbers that are closer to each in that space. Words like `dog` and `golden retriever` will be closer to each other than `man` and `banana`.
To convert from words to embeddings we need an embedding model. An embedding model is trained to find statistical similarities given a gigantic corpus of text — learning through millions of examples the frequencies of words being used in similar contexts. We can take documents we want to use with our Chatbot and chunk them up by paragraphs or sentences and encode them into this embedding space and then store them; This is where a vector database comes in as a convenient piece of software to store, search for nearest neighbors and retrieve relevant parts of documents.
Interestingly, embedding models and vector databases can also be used with images to retrieve similar images or by face detection to find similar faces. Creating embeddings, storing and even retrieving them are pretty quick functions in contrast to fine-tuning LLMs and orders of magnitude cheaper.
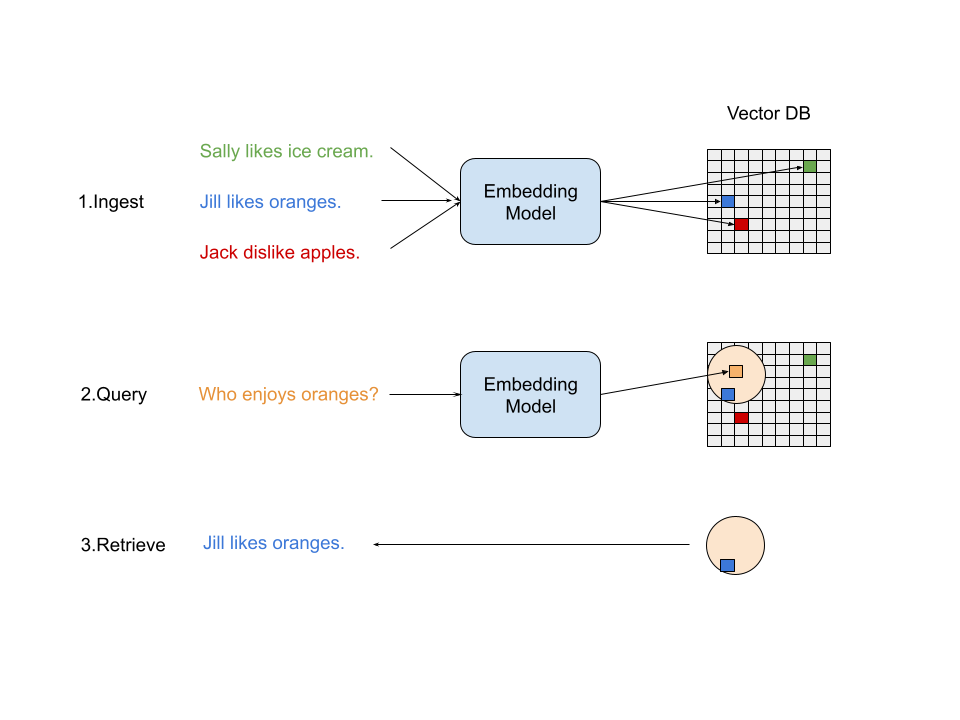
Data access in RAG is generally via three distinct steps:
- Ingest: Chunk up and ingest data using an embedding model and storing it in a vector database where things that are semantically similar will reside closer together.
- Query: Retrieve the items we have in our database by converting our query into an embedding and search for the closest neighbors to that embedding location.
- Retrieve: Use the retrieved data to seed a LLM.
Actually answering the question
Now that we have relevant articles we can utilize an LLM by passing in the question asked by the user as well as appending the relevant retrieve articles to produce a response. We can also use prompting to set a tone for the response – friendly and casual or all business. By passing in contextual information to the LLM and knowing the origin of that information (URLs or filenames) we can provide footnotes to the user and they can follow up by reading the full source material for further information.
An example prompt for the LLM as the system could be the following:
Context information is below.
———————
{context}
———————
Given the context information and no other prior knowledge, answer the query. If the context does not contain the answer, just say ‘I don’t know’ and don’t try to make up an answer. Respond with 12 words or less in an optimistic and casual but professional tone. You are an AI chat bot named Revvy that helps provide information and guidance about how to sell better.
Query: {query}
Answer:
The Recipe
Most RAG implementations will require a few ingredients that we discussed before:
- Documents: A knowledge base of documents you want the LLM to be able to use to answer queries. These could be PDFs or Google Docs or a Notion Site or even a transcription of a video.
- Embedding Model: Models that take words as input and provide the embeddings or vectors. Examples include OpenAI’s embeddings or BAAI/bge-large-en.
- Vector Database: A place to store your embeddings and their corresponding chunked documents and other metadata. The database will need to also be able to retrieve stored information given a query. Examples include Pinecone or Chroma.
- System Prompt: Instructions provided to a LLM to let it decide how to respond.
- Large Language Model: The LLM of choice for responding in a cogent manner given the query, the returned context and a prompt. Examples include Open AI’s GPT-4 Text Generation or Cohere’s Chat or Mistral AI’s Mixtral.
There are many options for each component that can be mixed and matched together to produce your own solution. Using LangChain or LlamaIndex allows you to produce easily interchangeable ingredients to find the perfect recipe.
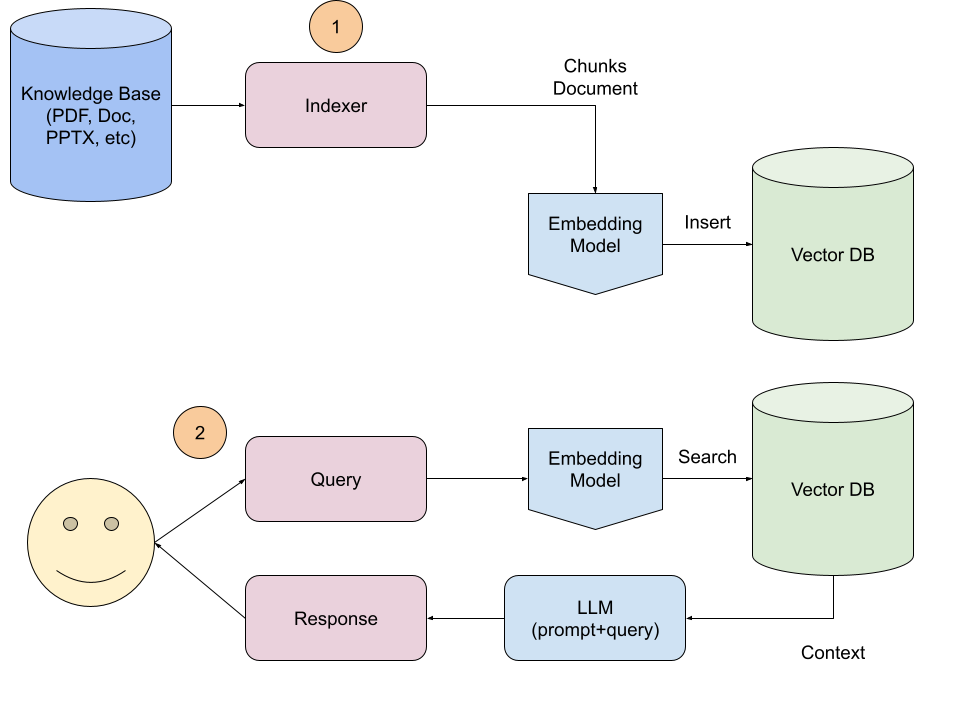
There are two specific sequences in RAG implementations; one for setup and one for information retrieval:
- Document Retrieval and Ingestion: Enterprise knowledge bases of PDFs and other documents are ingested by an Indexer service that loads them and chunks them into sentences or paragraphs and uses an Embedding Model to create embeddings for that chunk. Each embedding is then stored in a Vector DB with a link back to the original document. Metadata of each document may need to be stored with the chunk to provide it further context.
- User Query and Response Generation: When a User chats with the Enterprise App the user Query is also put through an Embedding Model to generate a embedding of the query and then searching for closest documents in the Vector DB. The retrieved chunks of text are passed into a LLM as a context and alongside the query and a prompt used to generate a response for the User.
Question Answered
Retrieval augmented generation offers a groundbreaking approach to chatbot development by combining the capabilities of LLMs with the precision of information retrieval. RAG models are trained on vast datasets of text, enabling them to generate accurate and coherent responses. Tenancy can also be baked into the querying layer to maintain data partitions for security and trust purposes.
RAG models’ accuracy, consistency, retrieval efficiency, personalization, and cost-effectiveness make them an ideal choice for enterprises seeking to enhance customer interactions and streamline their customer service operations.
Come back in the future to read more about challenges with RAG implementations, how to optimize them and what you can do to avoid common pitfalls.